Infrastructure as code, or IaC for short, is often touted as a solution for all the world's problems.
Imagine for a moment: no more configuration drift, clean and consistent deliverables, and all operators finally on the same page. What more could anyone ask for? I myself am fanatic about IaC, and you can often find me raving about all the problems it solves.
But it's not all sunshine and roses. If you've spent any time trying to manage IaC deployments, you soon discover that all that fancy infrastructure tooling requires one thing to manage them: infrastructure.
By the time you've gotten to a point where you can even use Terraform, Kubernetes, or whatever other fancy tools, you likely already have multiple layers of deployments that are not and cannot be managed by the tools you've just adopted.
This is the Catch-22, the Achilles' heel, of infrastructure development.
This is the Bootstrapping Problem.
What is "bootstrapping"?
Bootstrapping, in this context, describes self-sustaining processes that grow in size and complexity by chaining successive stages. Examples abound:
-
New programming language compilers are compiled using older compilers, which are built using older compilers, which use compilers written in other languages, etc., all the way back until someone had to first write one in machine language.
-
Computers boot using successively larger bootloaders, which each initialize the system just enough to support loading the next larger bootloader, until the operating system is fully loaded.
-
Software installers often have multiple stages so that earlier installers can update the later installers themselves.
Infrastructure goes through similar stages, whereby the introduction of a new capability to the organization makes it possible to introduce other capabilities that build on top. Each new layer depends on the previous layer and cannot exist without it:
-
The physical hardware must be working before you can install an OS.
-
A VM instance must be running before it can be provisioned with your software.
-
A container runtime must be installed before you can orchestrate containers.
-
And so on and so forth.
A case study
Let's see an example of the Bootstrapping Problem in action. Let's say you've got three infrastructure capabilities that you'd like to implement:
-
You want to host your own CI/CD runners. Bringing CI/CD runners home reduces your reliance on a third party and provides more control and visibility into what is critical infrastructure.
-
You want to use Terraform to deploy infrastructure. Adopting an immutable infrastructure strategy with Terraform leads to more predictable, flexible, and resilient deployments.
-
You want to use CI/CD to run Terraform. Standardizing around your CI/CD system simplifies your delivery system and makes cross-training your team members easier.

Each new capability sounds great, so you try to implement them.
You'll want to use Terraform to provision the runners, which you'll want to drive from CI/CD, which requires runners to be provisioned somewhere.
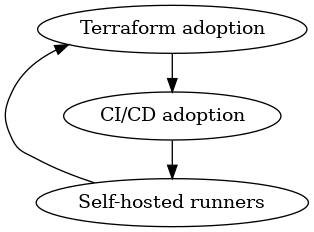
That, my friend, is a dependency cycle. Since this dependency cycle exists in the ordering of bootstrapping requirements, I like to call this situation a bootstrap loop.
Bootstrap loops are problematic because they must be resolved in order for bootstrapping to complete successfully. If the runners described above experience a failure, it will not be possible to use the existing Terraform automation to resolve it, because CI/CD will not be available to run it.
This can result in extended and difficult-to-resolve outages as teams scramble to find bootstrapping workarounds that circumvent existing processes.
How do bootstrap loops occur?
Bootstrap loops do not spontaneously occur, because it is impossible to provision infrastructure from nothing when it contains a bootstrap loop. Instead, they evolve over time as a result of changes in availability of infrastructure.
For the runner situation described above to occur, there must have existed another runner at some point to kick off the whole process:
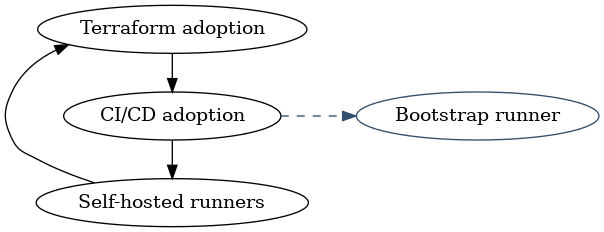
One of a few things might have happened:
-
The team used to pay for Cloud Runner minutes, but doesn't anymore.
-
The team decided to tear down their old runner box after deciding that they no longer needed it.
-
The person who ran the old runner box left the company.
Whatever the reason, there used to be a failover mechanism to kickstart this loop, but that mechanism disappeared when the organization forgot why they had it.
The Bootstrapping Problem can thus be described as the tendency to create bootstrap loops on accident as part of normal operation.
Solving the Bootstrap Problem
Preventing the introduction of bootstrap loops is essential to building a resilient infrastructure stack that can recover from failure without operator intervention.
1. Know the end state
Have an end state in mind for your infrastructure. You won't get there if you don't know what you want:
-
What tools will you use?
-
How will things fit together?
-
Where will you host?
-
Who needs access?
Answering these questions well requires experience. If you don't know what you need, find someone who does. It'll help you prevent expensive early mistakes.
2. Know the order of dependencies
If you are part of an organization of any size or complexity, it may seem like a constellation of interdependent services just exists and has happily done so for all time.
But this is not the case!
Everything depends on something else. Though you may not have experienced a scenario in which a bootstrapping requirement is currently unsatisfiable, these scenarios do exist.
Your first line of defense is knowing what things your thing needs in order to start successfully, and protecting that information.
3. Write everything down
Document, document, document! The earliest parts in this process are the most critical to document. The steps (create an account, save recovery codes, create an API key) seem so simple and obvious, and that's why they're likely to be forgotten.
In addition, these early steps exist outside of the platform you're building, so it is unlikely that they can be effectively automated.
4. Define a bootstrap procedure
Define a plan for getting from where you are to where you want to be. You'll likely need to solve the Bootstrapping Problem multiple times to arrive at your end state.
Here's a hypothetical plan to bootstrap a Kubernetes cluster with Ansible:
By defining this procedure, we always know the order of dependencies, and we know what layer to consult to recover if the layer above it is broken.
5. Use a third party
It's okay—stand on the shoulders of giants!
Even if you plan to host your own GitLab instance, having a few projects on GitLab.com to kickstart your delivery infrastructure is a good idea.
Build there for a few iterations until you have an self-hosted production environment to run GitLab. Then keep the GitLab.com infrastructure in your back pocket so that you are ready to bootstrap again if you ever need to.
Conclusion
Bootstrapping is a universal problem.
Your work is a result of your earlier work, and other people's work, much like you are a product of your past experiences, the experiences of those around you, and all of human history.
It really is turtles all the way down.
In that case, we should strive to know where we came from, how we got to where we are today, and preserve our history to defend our future.
If you do that much, you'll be able to weather any storm that comes your way, operational or otherwise.